How ChatGPT Helped Me Automate Supplier File Creation with Python
Overview
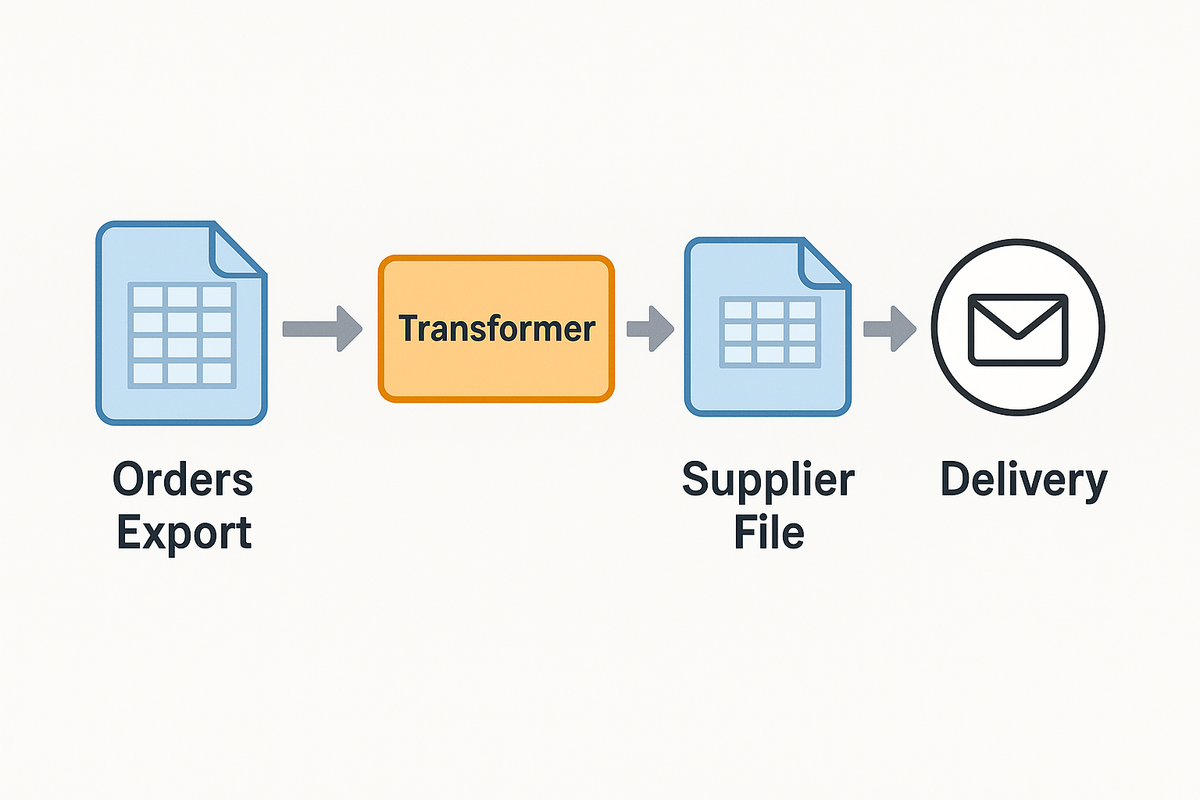
Every week, small business owners lose hours cleaning up spreadsheet exports — renaming columns, deleting unnecessary fields, and reformatting order data so their suppliers can actually use it.
With a bit of help from ChatGPT and Python, I built a config-driven script that automates the entire process. Now, a messy order export becomes a perfectly formatted supplier file in seconds.
Problem Statement
I came across a Reddit post from a small business owner who sells products online. Each week, they downloaded orders into Excel, manually cleaned the file, and sent it to their supplier.
Their pain points were familiar:
- Repetitive, manual cleanup of exported order data
- Inconsistent formatting that suppliers rejected
- Hours wasted renaming and deleting columns
The success metric was simple: one click to convert raw exports into supplier-ready files.
Prompting the LLM
I started by sharing the Reddit post with ChatGPT and asking for help:
ChatGPT analyzed the workflow, inferred typical columns (like order_id, sku, ship_address, etc.), and proposed a config-driven transformer. This meant I could define rules for each supplier in a small YAML file without changing code.
Once that idea clicked, I prompted again:
ChatGPT built a full end-to-end demo:
- Synthetic order data generated
- Config file describing how to map and rename fields
- Reusable Python script to transform the data
This iterative prompting process turned vague ideas into a production-ready workflow.
Generated Solution
Here’s the core of the final script (orders_to_supplier.py):
#!/usr/bin/env python3
import argparse, re
from pathlib import Path
from datetime import datetime, timedelta
import pandas as pd, yaml
def to_date(s): return pd.to_datetime(s, errors="coerce").strftime("%Y-%m-%d")
def po_date_plus(date_str, days=0):
dt = datetime.strptime(date_str, "%Y-%m-%d") + timedelta(days=days)
return dt.strftime("%Y-%m-%d")
def concat(*parts): return " ".join([p for p in parts if p and str(p).strip()])
def apply_computed(df, computed):
env = {"to_date": to_date, "po_date_plus": po_date_plus, "concat": concat, "pd": pd}
for col, expr in (computed or {}).items():
df[col] = df.apply(lambda row: eval(expr, {"__builtins__": {}}, {**row, **env}), axis=1)
return df
def transform(orders_path, cfg_path, out_dir):
cfg = yaml.safe_load(Path(cfg_path).read_text())
df = pd.read_csv(orders_path, dtype=str)
df.columns = [re.sub(r"\W+", "_", c).strip("_").lower() for c in df.columns]
# Rename and compute fields
ren = cfg["mappings"]["rename"]
df = df.rename(columns=ren)
df = apply_computed(df, cfg["mappings"].get("computed"))
# Final column order
df = df.rename(columns=cfg["output"]["rename_final"])
order = cfg["output"]["columns_order"]
for c in order:
if c not in df.columns: df[c] = ""
df = df[order]
# Save
out_path = Path(out_dir) / f"ACME_PO_{datetime.now():%Y%m%d}.csv"
df.to_csv(out_path, index=False)
return out_path
if __name__ == "__main__":
p = argparse.ArgumentParser()
p.add_argument("--orders", required=True)
p.add_argument("--config", required=True)
p.add_argument("--outdir", default="out")
args = p.parse_args()
print("Wrote:", transform(args.orders, args.config, args.outdir))Full code can be found on Github
Config Example (YAML)
filters:
include_financial_status: ["paid"]
mappings:
rename:
order_number: po_number
created_at: po_date
lineitem_sku: sku
lineitem_quantity: qty
computed:
po_date: "to_date(po_date)"
requested_ship_date: "po_date_plus(po_date, days=0)"
output:
columns_order: ["PO_NUMBER","PO_DATE","SKU","QTY"]
rename_final:
po_number: PO_NUMBER
po_date: PO_DATE
sku: SKU
qty: QTY
delivery:
format: csv
filename_pattern: "ACME_PO_{today}.csv"Example YAML file for vendor
Verification
I generated synthetic order data (20 line items) and ran the script:
python orders_to_supplier.py --orders exports/shop_orders_sample.csv \
--config configs/supplier_acme.yaml \
--outdir outBash command for running python script
Potential Enhancements
- Add email or SFTP delivery to send files directly to suppliers
- Store transformation logs for traceability
- Validate data with a schema tool like Pandera
- Create a simple web UI to upload files and select suppliers
Closing Thoughts
In just a few prompts and some Python polishing, I went from a Reddit complaint to a reusable automation.
The result isn’t just time saved—it’s mental energy reclaimed.
Instead of clicking through Excel, you define a process once, and your computer does the rest.
At Move, Minimally, this is the core idea: